A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
İçerik LessWrong tarafından sağlanmıştır. Bölümler, grafikler ve podcast açıklamaları dahil tüm podcast içeriği doğrudan LessWrong veya podcast platform ortağı tarafından yüklenir ve sağlanır. Birinin telif hakkıyla korunan çalışmanızı izniniz olmadan kullandığını düşünüyorsanız burada https://tr.player.fm/legal özetlenen süreci takip edebilirsiniz.
LessWrong (Curated & Popular) benzeri
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - Podcast Uygulaması
Player FM uygulamasıyla çevrimdışı Player FM !
Player FM uygulamasıyla çevrimdışı Player FM !

))
“Gradient Routing: Masking Gradients to Localize Computation in Neural Networks” by cloud, Jacob G-W, Evzen, Joseph Miller, TurnTrout
Manage episode 454603164 series 3364760
İçerik LessWrong tarafından sağlanmıştır. Bölümler, grafikler ve podcast açıklamaları dahil tüm podcast içeriği doğrudan LessWrong veya podcast platform ortağı tarafından yüklenir ve sağlanır. Birinin telif hakkıyla korunan çalışmanızı izniniz olmadan kullandığını düşünüyorsanız burada https://tr.player.fm/legal özetlenen süreci takip edebilirsiniz.
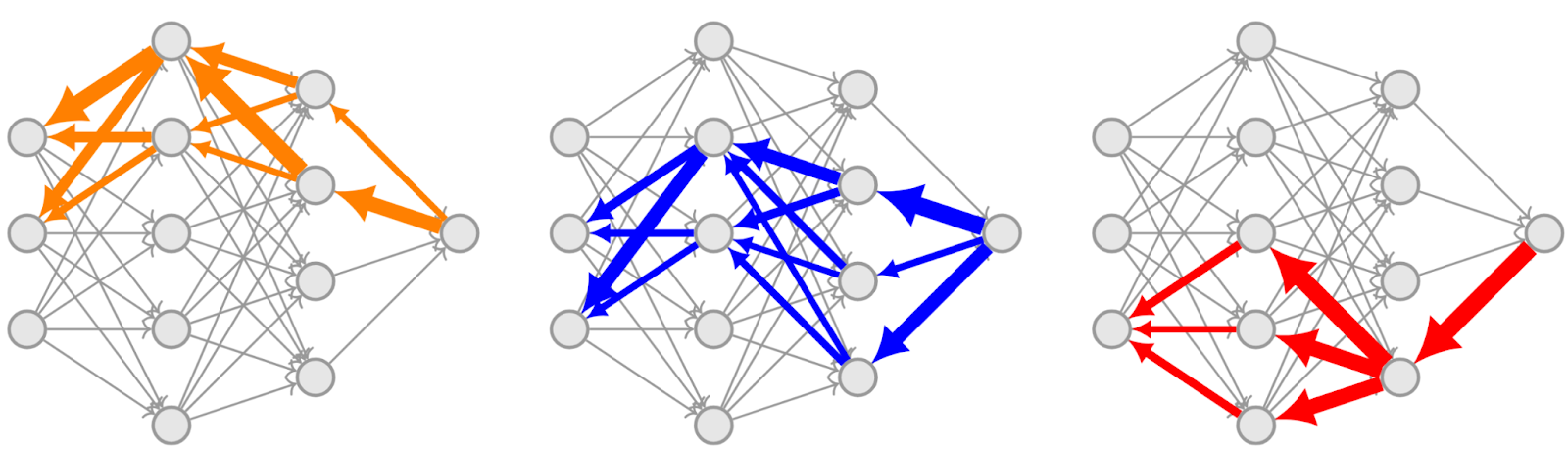
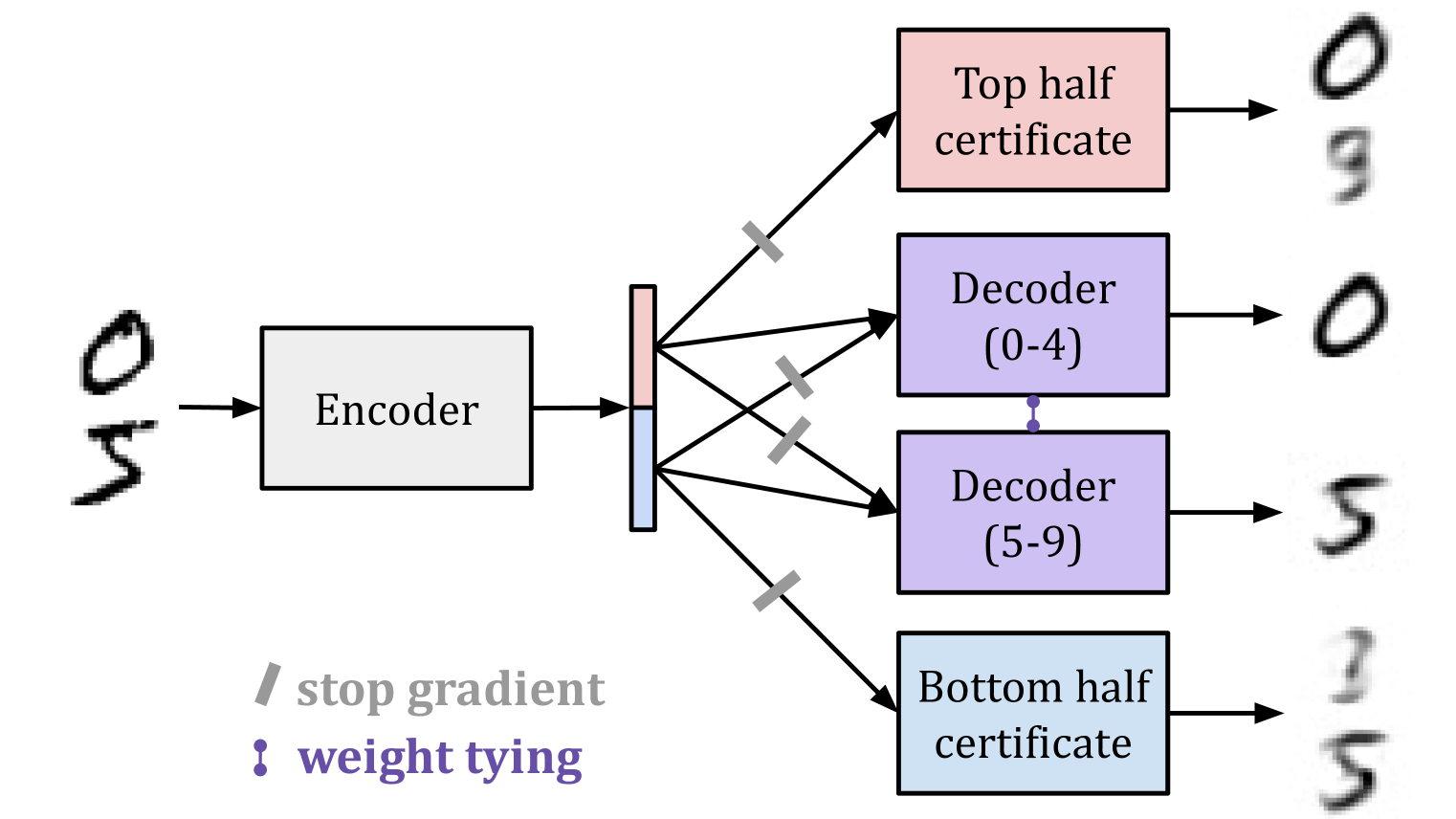
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
474 bölüm
Manage episode 454603164 series 3364760
İçerik LessWrong tarafından sağlanmıştır. Bölümler, grafikler ve podcast açıklamaları dahil tüm podcast içeriği doğrudan LessWrong veya podcast platform ortağı tarafından yüklenir ve sağlanır. Birinin telif hakkıyla korunan çalışmanızı izniniz olmadan kullandığını düşünüyorsanız burada https://tr.player.fm/legal özetlenen süreci takip edebilirsiniz.
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
474 bölüm
Tüm bölümler
×Player FM'e Hoş Geldiniz!
Player FM şu anda sizin için internetteki yüksek kalitedeki podcast'leri arıyor. En iyi podcast uygulaması ve Android, iPhone ve internet üzerinde çalışıyor. Aboneliklerinizi cihazlar arasında eş zamanlamak için üye olun.
LessWrong (Curated & Popular) benzeri
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - Podcast Uygulaması
Player FM uygulamasıyla çevrimdışı Player FM !
Player FM uygulamasıyla çevrimdışı Player FM !



